断点续传介绍
断点续传是为了在离线同步的时候,针对长时间同步任务如超过 1 天,如果在同步过程中由于某些原因导致任务失败,从头再来的话成本非常大,因此需要一个断点续传的功能从任务失败的地方继续。
原理
- 基于 flink 的 checkpoint,在 checkpoint 的时候 会存储 source 端最后一条数据的某个字段值,sink 端插件执行事务提交。
- 在任务失败,后续通过 checkpoint 重新运行时,source 端在生成 select 语句的时候将 state 里的值作为条件拼接进行数据的过滤,达到从上次失败位点进行恢复
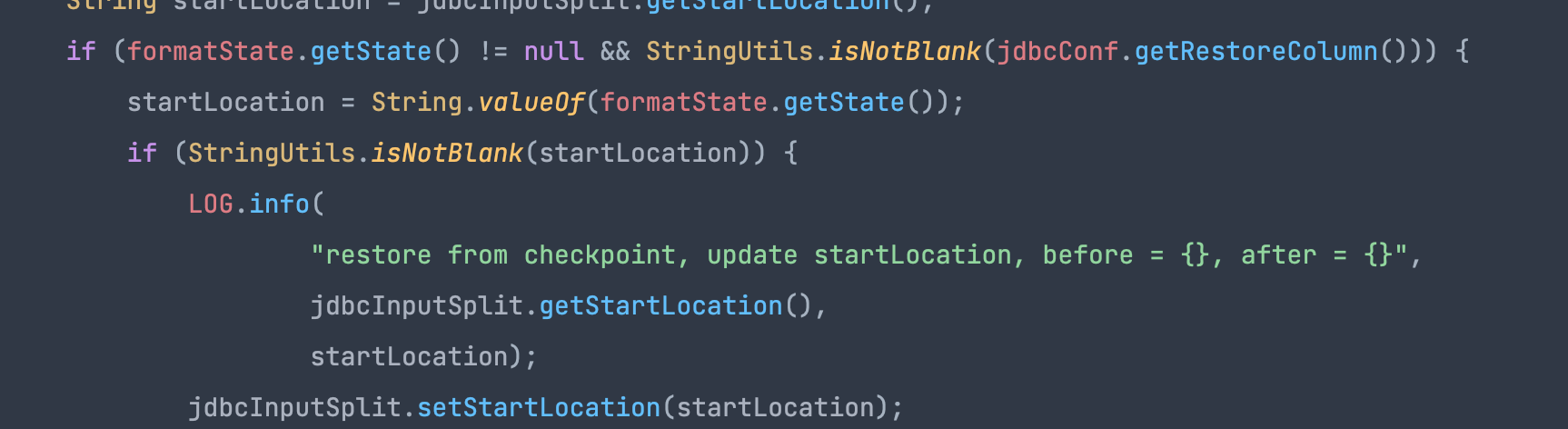
jdbcInputFormat 在拼接读取 sql 时,如果从 checkpoint 恢复的 state 不为空且 restoreColumn 不为空,则此时会将 checkpoint 里的 state 作为起点开始读取数据
适用场景
通过上述原理我们可知道 source 端必须是 RDB 类型插件,因为是通过 select 语句拼接 where 条件进行数据过滤达到断点续传的,同时断点续传需要指定一个字段作为过滤条件,且此字段要求是递增的
- 任务需要开启 checkpoint
- reader 为 RDB 的插件均支持且 writer 支持事务的插件(如 rdb filesystem 等),如果下游是幂等性则 writer 插件也不需要支持事务
- 作为断点续传的字段在源表里的数据是递增的,因为过滤条件是 >
参数配置
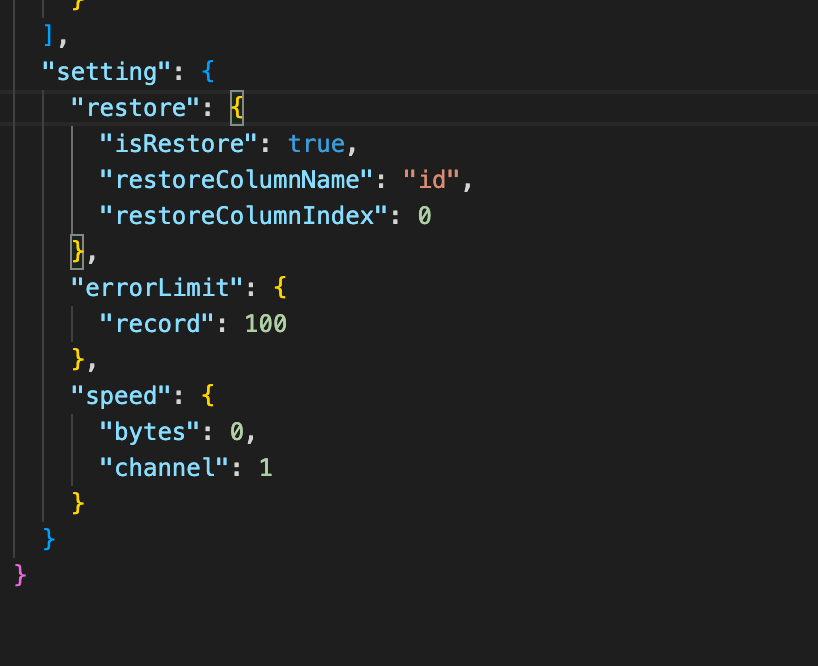
开启 restore 需要在脚本的 restore 里配置相关参数
| 参数 | 含义 | 类型 |
|---|---|---|
| isResore | 是否开启断点续传,true 代表开启断点续传,默认不开启 | boolean |
| restoreColumnName | 断点续传字段 | string |
| restoreColumnIndex | 断点续传字段在 reader 里的 column 的位置 | int |
示例