
背景
目前任务对脏数据的处理仅仅是日志打印,这样显然是无法应对客户多变的使用场景。
方案
整体架构采用生产者-消费者模式,任务启动过程中,同时将 Manager 初始化并启动 Consumer 异步线程池,仅需在 BaseRichInputFormat 和 BaseRichOutputFormat 调用 Manager 的 collect() 方法收集脏数据即可。
流程图
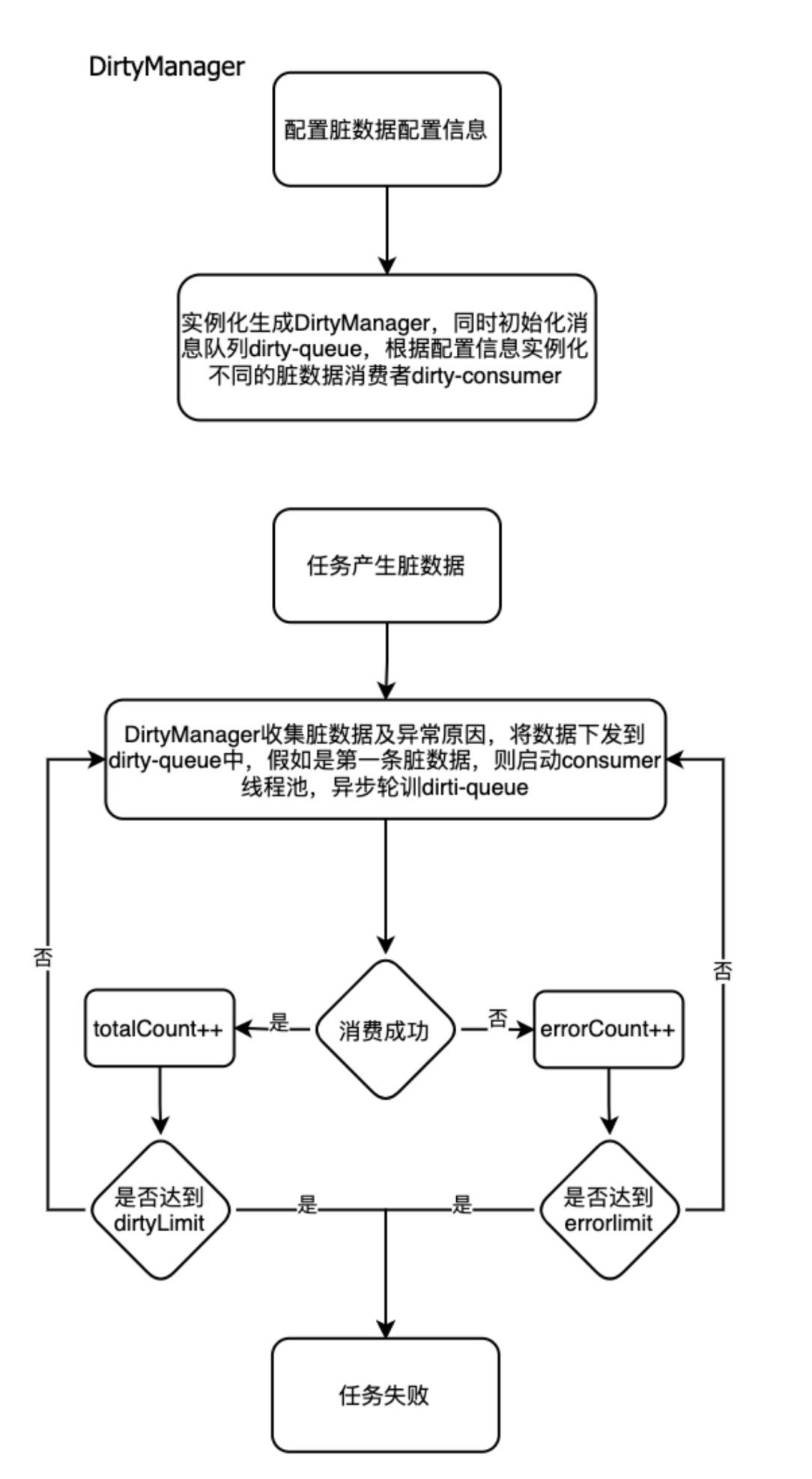
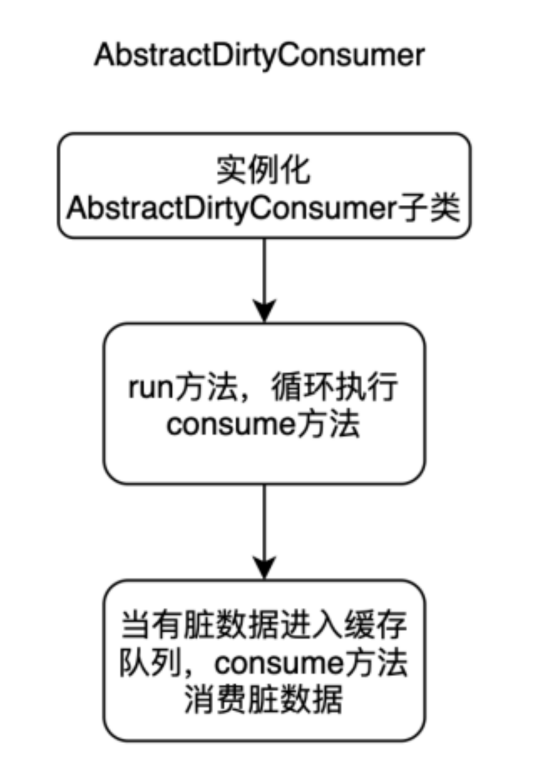
详细描述
任务配置参数
对应 Java 实体类 - DirtyConf
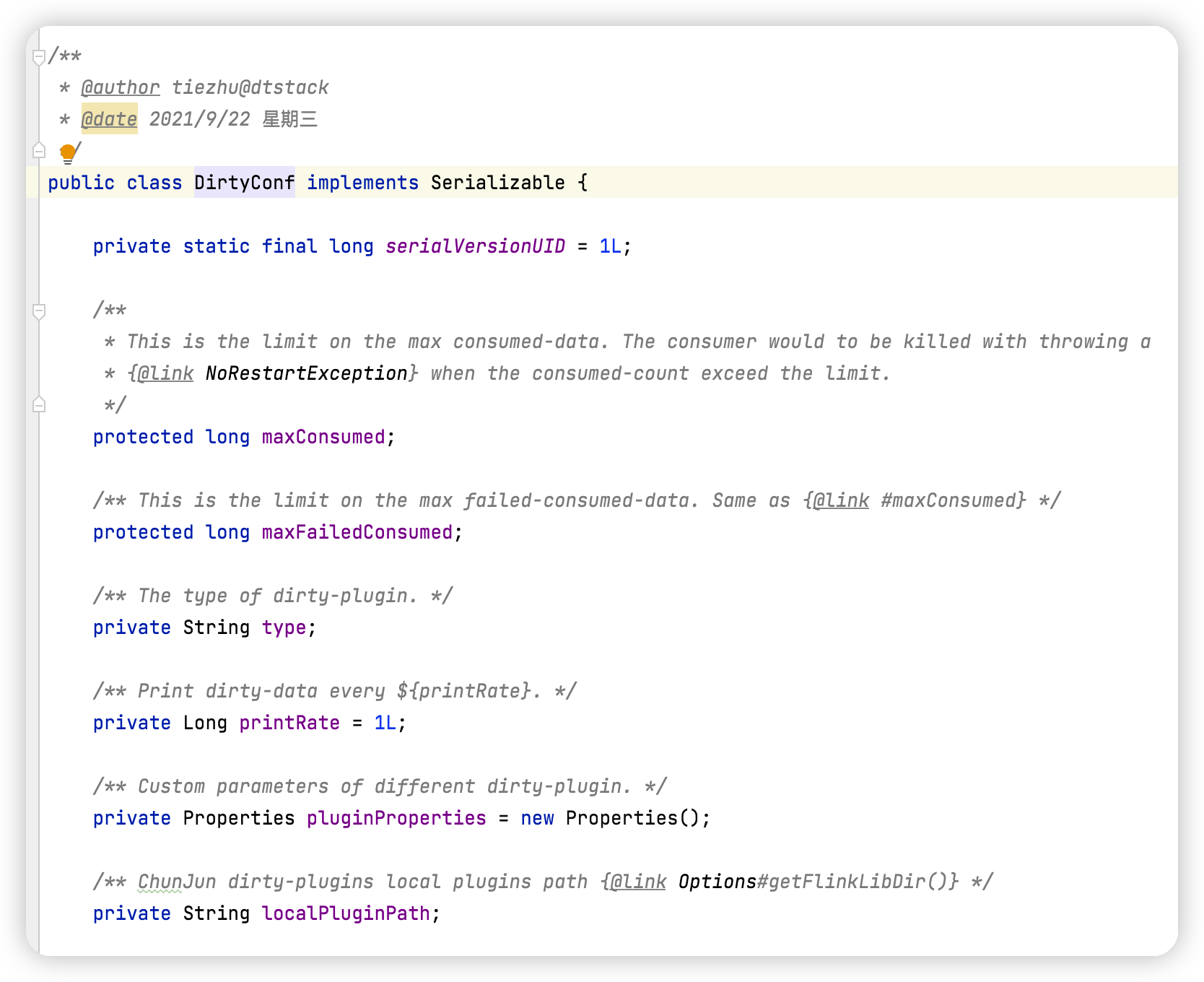
- type 插件类型,必填项,根据 type 动态加载对应的插件;
- printRate 脏数据在日志中的打印频率,默认值修改为 1,表示默认脏数据信息都会打印到日志文件中,同时,如果 printRate <= 0,表示不打印任何脏数据信息;
- errorLimit 脏数据在插件中,处理失败的条数限制,当处理失败的脏数据条数超过这个限制时,任务抛出 NoRestartException,即任务失败且不重试;默认值修改为 1,如果 errorLimit < 0,表示任务容忍所有的异常,不失败;
- totalLimit 脏数据总条数限制,即收集到的脏数据超过这个限制时,任务抛出 NoRestartException,即任务失败且不重试;默认值修改为 1,如果 totalLimit < 0,表示任务容忍所有的异常,不失败;
- properties 各自插件的参数配置
脏数据插件管理者
对应 Java 实体类 - DirtyManager
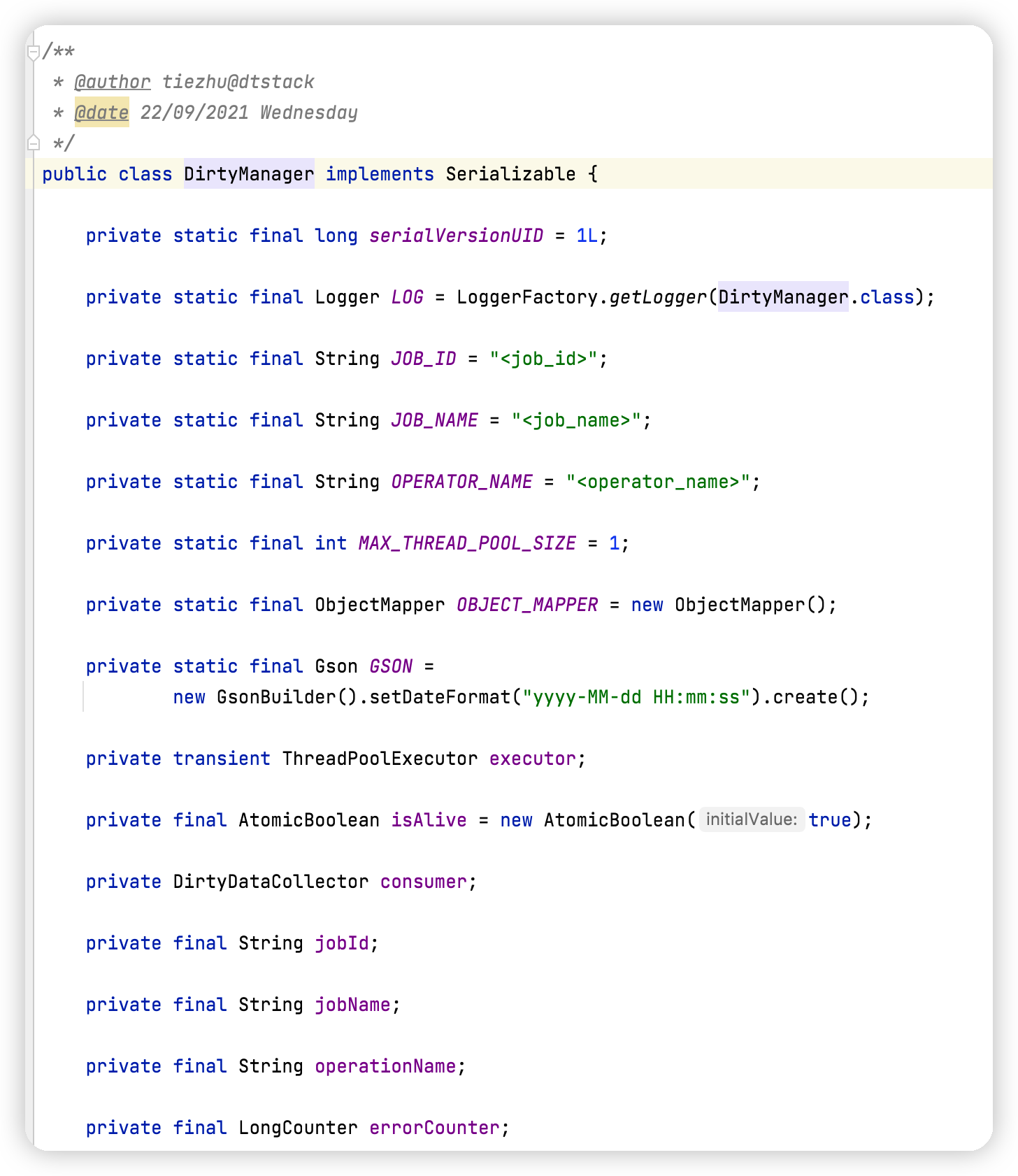
Manager 主要维护着脏数据消费者 Consumer 和 一个异步线程池;
主要作用是收集脏数据,并下发到 Consumer 队列中
调用 collect() 方法 BaseRichInputFormat
脏数据插件消费者 对应 Java 实体类 - AbstractDirtyConsumer Consumer 主要维护着一个消息队列,中间缓存着脏数据信息;
run() 方法 主要逻辑是消费队列中的脏数据,consume() 方法交给子类去实现;如果在 consume 过程中出现了异常,那么 errorCounter 计数加一。
consume() 方法 处理脏数据的具体逻辑,交由子类实现,根据插件的不同,对脏数据处理逻辑也会有所不同。
以下参数在 ChunJun 启动参数-confProp 中
chunjun.dirty-data.output-type = log/jdbc
chunjun.dirty-data.max-rows = 1000 // total limit
chunjun.dirty-data.max-collect-failed-rows = 1000 // error limit
chunjun.dirty-data.jdbc.url=
chunjun.dirty-data.jdbc.username=
chunjun.dirty-data.jdbc.password=
chunjun.dirty-data.jdbc.database= // database 可以写在 url
chunjun.dirty-data.jdbc.table=
chunjun.dirty-data.log.print-interval= 500
JDBC 建表语句(MySQL)
CREATE TABLE IF NOT EXISTS chunjun_dirty_data
(
job_id VARCHAR(32) NOT NULL COMMENT 'Flink Job Id',
job_name VARCHAR(255) NOT NULL COMMENT 'Flink Job Name',
operator_name VARCHAR(255) NOT NULL COMMENT '出现异常数据的算子名,包含表名',
dirty_data TEXT NOT NULL COMMENT '脏数据的异常数据',
error_message TEXT COMMENT '脏数据中异常原因',
field_name VARCHAR(255) COMMENT '脏数据中异常字段名',
create_time TIMESTAMP(6) DEFAULT CURRENT_TIMESTAMP(6) NOT NULL ON UPDATE CURRENT_TIMESTAMP(6) COMMENT '脏数据出现的时间点'
)
COMMENT '存储脏数据';
CREATE INDEX idx_job_id ON chunjun_dirty_data (job_id);
CREATE INDEX idx_operator_name ON chunjun_dirty_data(operator_name);
CREATE INDEX idx_create_time ON chunjun_dirty_data(create_time);
Metircs
chunjun_DirtyData_count
chunjun_DirtyData_collectFailedCount
项目目录结构
父模块
chunjun-dirty
子模块
chunjun-dirty-mysql chunjun-dirty-log

